Dr. Csallner András Erik: Bevezetés az SPSS statisztikai programcsomag használatába
Menüelemek
File menü
A fájlkezelő műveleteket találjuk benne:
- New: új adat- (Data) vagy output fájl (Output) létrehozása.
- Open: már létező adatfájl vagy output állomány megnyitása.
- Open Database: új vagy már létező SQL szervezésű adatfájl megnyitása.
- Read Text Data: szövegformátumú állomány megnyitása.
- Save: az adott fájl mentése a kijelölt helyre.
- Save As: kijelöljük, hogy hova, milyen néven és fájltípusban legyen az adott fájl mentve – a „Save” első használat során automatikusan ideirányítja a felhasználót.
- Save All Data: összes nyitott állomány mentése.
- Mark File Read Only: az adott fájl megjelölése oly módon, hogy ezt követően csak olvasni lehessen, vagyis semmilyen javítás nem lesz engedélyezett rajta a későbbiek folyamán.
- Rename Dataset: adatbázis el- vagy átnevezése – a fájlnév mellett az adatbázis is rendelkezhet saját névvel, amely akkor hasznos, ha több azonos nevű fájl létezik.
- Display Data File Information: A .sav kiterjesztésű fájlokról ad információt egy külön ablakban. A WORKING FILE-ra kattintva a betöltött fájlról kapunk információkat (variable: változó, position: pozíciója, label: címke, measurement level: mérési szint, column width: oszlopszélesség, alignment: igazítás módja), míg az EXTERNAL FILE során egy külső adatbázisról tudjuk meg ezeket az adatokat.
- Cache Data: a Cash Now futtatása alatt az adatokon nem lehet változtatni, ám az adatok áttekintése gyorsabbá válik a folyamat után.
- Print: nyomtatási beállítások megadása, amely az adott ablakra vonatkozik.
- Print View: a várható eredmény megtekintésére szolgáló ún. nyomtatási kép.
- Switch Server: szervergépre való csatlakozás.
- Stop Processor: az SPSS számolási egységeinek leállítása, amely hibásan kiadott nagy számolási- és időigényű feladatoknál hasznos.
- Recently Used Data: legutóbb használt .sav kiterjesztésű fájlok elérése.
- Recently Used Files: legutóbb használt nem .sav kiterjesztésű fájlok elérése.
- Exit: program bezárása.
Edit menü
Adatszerkesztéssel kapcsolatos programok, illetve utasítások tartoznak ide:
- Undo: utoljára kiadott utasítás visszavonása.
- Redo: az „Undo” során visszavontakat teszi érvényessé.
- Cut: a kijelölt részlet kivágása.
- Copy: a kijelölt részlet másolása – a „Cut” és a „Copy” során használtakat más alkalmazásba is be lehet illeszteni, mert azt a program a Windows vágóasztalára helyezi.
- Paste: A „Cut” és a „Copy” során kijelöltek adott helyre másolása.
- Paste Variables: előzőleg kiválasztottak bemásolása.
- Clear: törlés – sorok és oszlopok törlésénél nem lesznek üres cellák.
- Insert Variable: új változó, oszlop beillesztése a kijelölt helytől balra – ikonja oszlopok közötti kék ék.
- Insert Cases: új eset, sor beillesztése a kijelölt hely fölé – ikonja sorok közti piros ék.
- Find: változók keresésére lehet alkalmazni, esetekre nem – ikonja távcső.
- Go to Case: megadott esethez viszi a kurzort – ikonja sor fölött álló piros nyíl.
- Options: SPSS aktív ablakára vonatkozó beállítások.
Legfontosabb a GENERAL fül: vagy a változó nevét (Display Name), vagy azok jelentését (Display Labels) látjuk – később bevont változók esetén a jelentés szerepel a felsorolásban, a nevük zárójelben utánuk. Ha a változók nevét jelöljük be, akkor ez az adat áll rendelkezésre a későbbi statisztikai elemzések során.
- Viewer: output ablakok beállítása (betűméret és stílus, szám).
- Output Labels: az output ablakban megjelenő táblázatokban és grafikonokban a változó neve, jelentése vagy mindkét adat megjelenítésének a beállítása.
- Charts: az output ablak grafikonbeállításai.
- Interactive: állomány nyomtatási és mentési beállításai.
- Pivot Tables: az output ablak táblázatainak formai beállításai.
- Currency: pénznemek formai beállításai – tizedesek tagolása, / . ; toldalékokat tartalmaz.
- Data: adatok beállításai: új numerikus adatok formátuma (DISPLAY FORMAT FOR NEW NUMERIC VARIABLES), vagy véletlenszám-generátor (RANDOM NUMBER GENERATOR).
View menü
Az aktív ablak megjelenítésére vonatkozó beállításait hajtjuk végre:
- Status Bar: állapotsor beállítása, processzor ellenőrzése – ez az állapotsor aktív állapota során lehetséges.
- Toolbars: eszköztár megjelenítése, illetve az itt megjelenő parancsok, ikonok beállítása.
- Fonts: az éppen használt betű típusáért, stílusáért, méretéért felelős.
- Grid Lines: ha aktív, akkor az ablak rácsozása látható, ha inaktív, akkor nem.
- Value Labels (értékcímkék): amennyiben aktív, akkor a Variable View során meghatározott változójelentést használja a Data View ablak – ha inaktív, akkor a változó értékét.
- Variables / Data: a két ablak között vált.
Data menü
Az adatkezelési lehetőségek:
- Define variables properties: változók tulajdonságainak meghatározása/ megváltoztatása. Annyiban tér el a Variable View-tól, hogy itt az értékekhez tartozó esetek kilistázhatóak.
- Copy data properties: adattulajdonságok másolása vagy egy külső forrásból ide, vagy pedig innen egy célfájlba.
- Define Dates: a dátumformátumban lévő változók meghatározása – év, hónap, nap és másodperc pontosságú időpontok esetén.
- Define Multiple Response Sets: többválaszos változó definiálása, amelyeket az ANALYZE / TABLES menüpontban a CUSTOM TABLES vagy a MULTIPLE RESPONSE SETS opció alatt lehet felhasználni táblázat részeiként. A másik lehetőség (ANALYSE – MULTIPLE RESPONSE – DEFINE SETS) csak akkor lesz aktív, ha a változó meghatározása már megtörtént. A menüpontok működése hasonló: azokat a változókat, amelyeket elemezni szeretnénk a „Variables in set” ablakba helyezzük, majd megadjuk, hogy egy értéket ’dichotomies’ (igen-nem válaszok esetén) vagy több értéket ’categories’ (több kategória esetén, felsoroláskor) számolunk össze – ha ezt az opciót választjuk, akkor minimum- és maximumérték megadása kötelező. Ezt követően nevet kell adni az új változónak, majd használni – ez az „Add” gomb megnyomása után lehetséges. Gyakran átkódolás szükséges ahhoz, hogy ezek csak a számunkra megfelelő értékeket tartalmazzák.
- Identify Duplicate Cases: többször előforduló esetek azonosítása akár egy változóval, akár az összessel. A program meghatározza az ismétlődő (Duplicate) és az egyedülálló adatokat (Unique/ Primary). Az új változó Primary Last néven szerepel – hasonló elemekből álló kategóriában az utolsó elem az elsődleges szerepű.
- Sort Cases: az esetek sorba rendezése az általunk megadott szempontok szerint.
- Transpose: az adatbázis sorainak és oszlopainak felcserélése, amely során az eddigi funkciójuk is megváltozik.
- Restructure: a „Transpose” menüpont kiegészítése – nemcsak a teljes adatbázist lehet felcserélni, hanem néhány általunk kijelöltet is.
- Merge files: az esetek és a változók összefűzését teszi lehetővé egy vagy több állomány esetén.
- Aggregate: adatok tömörítésére szolgál az általunk megadott összevonás által. Megkülönböztetünk csoportosító (break variable) és összevonni kívánt változót (summaries of variables). Az új változót vagy az eredeti adatbázisba helyezzük vissza, vagy pedig másik fájlban helyezzük el.
- Orthogonal Design: a merőleges kivitelezést az összekapcsolt elemzések során használják, amelyet e könyv nem taglal.
- Copy Dataset: az egész adatbázis másolása, amely során megbizonyosodik a program használója arról, hogy az elvégezni kívánt változtatások során az eredeti állományt nem írja felül.
- Split File: a program csoportokra bontja az állományt, hogy ezeken hajtsa végre a statisztikai elemzést – aktiválása során a „Split File On” felirat jelenik meg, ikonja egy kettévágott adatbázis.
- Select Cases: kizár az SPSS bizonyos elemeket az elemzésből az általunk megadott feltételeknek megfelelően – az eljárás során feleslegessé vált elemek fekete vonallal lesznek áthúzva, valamint a „Filter On” felirat látható.
- Weight Cases: javítási lehetőség egyes elemek súlyozása során – túlprezentáltakat kisebb, az alulprezentáltakat nagyobb értékkel korrigálja a program.
- Data / Merge Files – Fájlok egyesítése
- A régi állományhoz való hozzárendelés lépései:
- 1. lépés: a DATA menü MERGE FILES menüpontját kell használni:
- Add Cases: a változók megegyeznek az eredeti adatbázissal, így csak az új eseteket illesztjük a régiekhez.
- Add Variables: az esetek megegyeznek az eredetivel, így csak az új változókat illesztjük a régiekhez.
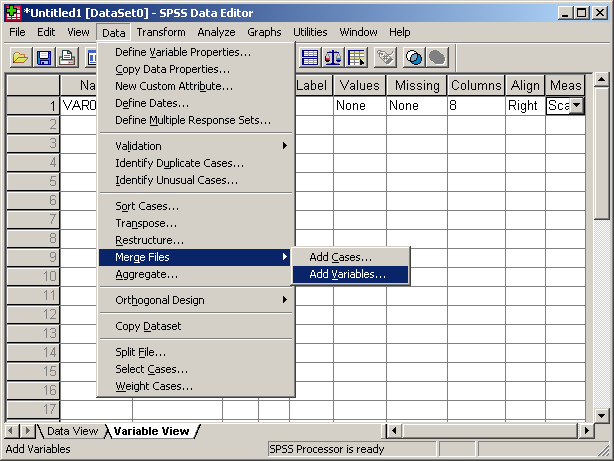
5. ábra
- 2. lépés: a hozzácsatolni kívánt fájl megadása külső adatfájlt használva (an external SPSS data file).
- 3. lépés: azok az adatok, amelyet a program párosítani tudott a „VARIABLES IN NEW ACTIVE DATASET” ablakban jelennek meg – „OK” gombra kattintva a kibővített adatbázis jelenik meg.
- Data / Select Cases – Esetek kiválasztása
- Ezt a menüpontot akkor használjuk, amikor az adatelemzésben nincs minden adatra szükség, mert csak az eseteket vizsgáljuk.
- 1. lépés: „DATA menü SELECT CASES” menüpont megnyitása – szűrőfeltételeket is meg kell adni az alábbi opciók segítségével:
- All Cases: nincs szűrés, minden eset részt vesz az elemzésben.
- If condition is satisfied: elemeket választunk ki relációs jelek, függvények, logikai feladatok során.
- Random sample of cases: véletlenszerűen választja ki az eseteket vagy százalékos arány (approximately) vagy konkrét számmennyiség (exactly) megadásával.
- Based on time or case range: sorrendiség vagy szűrési idő szerint választ.
- Use filter variable: megadunk egy változót, amit a rendszer szűrőváltozóként használ.
- Output: a szűrés eredményének sorsát adjuk meg.
- Filter out unselected cases: a nem választott adatok az ablakban maradnak, ám figyelmen kívüliek – „Filter On” felirat.
- Copy selected cases to a new dataset: új adatbázisba kerülnek a kiválasztott adatok.
- Delete unselected cases: töröljük az adatbázisból a nem kiválasztott adatokat – használata nem ajánlott.
- 2. lépés: „IF” szűrőfeltétel alkalmazása során szűkítjük le az adatbázist, ezt követően a „CONTINUE” gombra kattintva lépünk tovább.
- 3. lépés: a „Filter out unselected cases” beállítás választása során a többi adat nem kerül törlésre, csupán figyelmen kívül hagyja a program az elemzés során – ezeknek az elemeknek a jelölése áthúzással történik, valamint egy új változó keletkezik, a „filter_$”, amely értékei a 0-t (nincsenek benne az vizsgálatban, vagyis az áthúzott elemek) és az 1-et (benne vannak) vehetik fel. (A szűrés visszaállítása nélkülözhetetlen a folyamat lefutása után – erre az „All cases” opció választásával van lehetőség.)
Transform menü
Ez a menü is adatkezelési lehetőség – főleg akkor, ha régi változókból állítunk elő újat, vagy eseteket újrakódolunk.
- Compute – új változó számítása
- Ez a menüpont új adatbázis előállítását teszi lehetővé a régi felhasználásával – a kettő között vagy függvényszerű vagy logikai viszony van.

6. ábra
- 1. lépés: A TRANSFORM / COMPUTE választásával kapott ablakban a NUMERIC EXPRESSION panelbe azt a képletet kell bevinni, amely segítségével az új adatbázist szeretnénk létrehozni. A TARGET VARIABLE szövegdobozba pedig ennek a nevét írjuk be.
- 2. lépés: A TYPE AND LABEL opció használatával a változó tágabb értelemben vett jelentését adjuk meg a „Label” sorban, amely a „Continue” lenyomásával rögzül.
- 3. lépés: a szűrőfeltételek megadása az alapablakban lehetséges, ha az „If” gombra kattintunk.
- 4. lépés: A „Continue” majd az „Ok” egymást követő lenyomásával a végeredmény megjelenik.
- Recode – átkódolás
- A már létező változók átkódolását, módosítását végezzük el ebben a menüben az alábbi lehetőségek szerint:
- Into Same Variables (ugyanazokba a kódokba): ha az átkódolás után nincsen szükség az eredeti változóra, akkor ez felülírja a régit.
- Into Different Variables (más változókba): megtartja a felülírandó adatot – új változó nevét és paraméterét meg kell adni – ez a módszer eredményesebb lehet a későbbi vizsgálatok során, hiszen nem történik adatvesztés.
- 1. lépés: TRANSFORM / RECODE / INTO DIFFERENT VARIABLES alkalmazása.

7. ábra
- 2. lépés: Pl. városokat jelképező kódok alapján történik a szelekció – ez azonban szöveges változót eredményez. Ezt a STRING VARIABLE à OUTPUT VARIABLE panel jelzi. Ez utóbbi nevét (Name) és címkéjét (Label) megadjuk – a változtatás mentése a „Change” gomb lenyomásával történik. Szűrőfeltételeket az „If”-fel adunk meg. A megfeleltetéseket (régi változó – új változó) az „Old and New Values” gomb megnyomásával rögzítjük.
- 3.lépés: A „Convert numeric strings to numbers” opció bejelölése elengedhetetlen, hiszen szöveget alakítottunk adattá. Az „Add”-del rögzítjük a szelektálást. A program lehetőséget ad még a rendszer vagy a felhasználó hibájából adódó hiány jelölésére (System- or user-missing) és a nem szöveges változók esetén intervallumot adhatunk meg.
- Az eredményt a „Continue” és az „Ok” egymást követő lenyomásával kapjuk meg. Az új változóhoz értéket kell még rendelni a Variable View lapon.
- Az érték azonnali (Calculate Values Immediately) vagy használat előtti kiszámításának (Calculate Values Before Use) a beállítására is van lehetőség: EDIT / OPTIONS / DATA / TRANSFORMATION AND MERGE OPTIONS.
- Count – az előfordulások megszámlálása
- Olyan új változót hozunk létre, amely tartalmazza a régi változók együttes előfordulásait.
- 1.lépés: TRANSFORM / COUNT alkalmazása.
- 2.lépés: a panel kitöltése oly módon, hogy a „Target Variable” tartalmazza az új változó nevét, a „Target Label” a jelentését, a „Numeric Variables” pedig a csoportosítás alapjául szolgáló régi változókat tartalmazza. A „Define Values”-ra kattintva lépünk tovább.
- 3.lépés: Values to Count” opcióra van szükség a feladat befejezéséhez: itt az előzetesen bevont változók értékeit kell megadni:
- A, „Value” ablakba az értékeket bevisszük az „Add” segítségével
- B, „Range” (terjedelem) lehetőségbe begépeljük, hogy mettől meddig foglaljuk bele a régi értékeket. Pl. 10 through 28, azaz 10-től 28-ig.
- C, „Range / Lowest through value”, amely során a felső korlátot adjuk meg.
- A szűrőfeltételeket az „If”-fel lehet megadni.
- Az új változó újoszlopként(!) jelenik meg.
- Rank Cases – esetek rangsorolása
- Az eseteket rangsorolja az megadott változók értékei alapján – ezt a „VARIABLES” ablakba visszük be, kivéve, ha csoportokon belül akarjuk a sorrendiséget kiszámoltatni (ez esetben a „BY” ablakot kell kitölteni). Be lehet állítani, hogy az 1. helyezéshez a legnagyobb (Largest Value) vagy a legkisebb érték (Smallest Value) kapcsolódjon: ASSIGN RANK 1 TO. A RANK TYPES segítségével speciális rangsorolási eljárásokat határozhatunk meg, míg a „TIES” annak megadására ad lehetőséget, hogy az azonos értékű változók milyen rangot kapjanak.
- Automatic Record: Automatikus átkódolás
- Azokat a változóértékeket kódolja át, amelyek nem alkalmasak a feldolgozásra, vagyis amelyeket statisztikai elemzéshez nem lehet felhasználni. Az átkódolandó változókat átnevezzük a „NEW NAME” segítségével – meghatározhatjuk azt is, hogy a folyamatot a rendszer a legnagyobb (RECORDE STARTING FROM HIGHEST VALUE) vagy a legkisebb elemmel kezdje.
- Date / Time
- Az idővel és a dátummal kapcsolatos változtatásokat és beállításokat hajthatunk itt végre.
- Create Time Series: idősorok létrehozása
- Jelen esetben az idősor olyan értékeket tartalmaz, amelyek időben egymás után következnek. Az ilyen jellegű változókból a „CREATE TIME SERIES” menüponttal más jellegű idősort lehet létrehozni. Az adatok olyan különböző időkben lezajlott megfigyeléseket tartalmaznak, amelyek között az eltelt idő, vagyis az intervallum egyenlő. A feldolgozandó adatok kiválasztását követően annak a függvénynek a típusát kell meghatározni („FUNCTION” panel”), amellyel az átalakítást hajtjuk végre – lehet szezonális ingadozás, simítás, mozgóátlagolás, stb. A folyamatot a „Change” feliratú gombra kattintva zárjuk.
- Replace Missing Values: Hiányzó értékek pótlása
- Akkor használjuk ezt az alkalmazást, ha nem használtunk hiányzóérték-kódot, és ha minden esetnél szükséges érvényes ismérvérték. A változók megadása után a „METHOD” segítségével választjuk ki azokat a lehetséges értékeket, amelyekkel a hiányzó adatokat kívánjuk helyettesíteni – teljes átlag, szomszédos pontok átlaga, szomszédos pontok mediánja, lineáris interpoláció, az adott pontra vonatkozó lineáris trend.
- Random Number Generators: Véletlenszám-generátor
- Két fajtát tartalmaz a program: SPSS 12 COMPATIBLE-t és MERSENNE TWISTER-t. Míg az előbbi elavult, de a program 12-es verziójával kompatibilis, addig az utóbbi a modernebb és megbízhatóbb. Fix indulóértéket (Fixed Value) az ACTIVE GENERATOR INITIALIZATION menüpontban adhatunk meg.
- Visual Bander: Változók kategorizálása
- Numerikus változó elemzésénél szükség van az eredeti (folytonos) kategóriákba sorolt változatára is. Ide sorolható a jövedelem elemzése. Ehhez grafikai ábrát hoz létre a program, amelyben a felhasználó adja meg a kategóriák alsó és felső értékeit.
- Az osztópontokat a MAKE CUTPOINTS panelben határozzuk meg:
- A, Equal Width Intervals: azonos szélességű intervallumok létrehozása – megadjuk az első osztópontot, az osztópontok számát és szélességét.
- B, Equal Percentiles: ugyanannyi esetet tartalmazó intervallum, amelyben a szélesség nem mindig azonos: három kategória létrehozásához két osztópont szükséges (ezt a NUMBER OF CUTPOINTS pontban állítjuk be).
- C, Cutpoints at Mean and Selected Standard Deviations: meghatározzuk, hogy az átlagon kívül mely szórásértékeknél legyenek osztópontok.
- A kiinduló ábrához az „Apply” gomb megnyomásával jutunk vissza – ekkor már a két osztópont értékei megjelenítettek, ezeket a hisztogram kék vonallal jelöli. A MAKE LABELS paranccsal a program hozzárendeli az értékekhez (Value) a címkét (Label).
- Analyze menü
- A statisztikai számításokhoz szükséges eszközök többsége itt található, a fontosabb menüpontok tárgyalására a későbbi fejezetekben konkrét példákon keresztül kerül sor.
8. ábra
- Graphs menü (ábrázolás)
- Az itt található grafikonok, ábrák és diagramok a statisztikai elemzés eredményeit és adatait teszik szemléletesebbé, könnyen és gyorsan áttekinthetővé.
- Interactive: az említett lehetőségek finombeállításai.
- Ultilities menü
- Variables: változók paramétereit egyesével megmutatja egy output ablakban.
- OMS „Output Managent System”Control Panel (kimeneteli menedzsmentrendszer): a kiválasztott kategóriákat különféle kimeneti-formátumba írja – pl. sav, xml, html, text.
- OMS Identifiers: OMS parancsok írása
- Data File Comments: adatfájl ellátása megjegyzésekkel
- Define Sets: a változókat részhalmazra szűkíti az ide felvett változók megjelölésével és névvel történő ellátásával
- Use Sets: az elemzés leszűkítése a változók egy adott részhalmazára
- Menu Editor: menüsor szerkesztése, testre szabása
- Window menü (ablakkezelés)
- A felhasznált ablakok méreteinek beállítása.
- Minimize All Window: összes ablakot lekicsinyíti, és a táblára helyezi
- Split: képernyő felosztása oly módon, hogy a kisablakokat egymástól függetlenül lehessen mozgatni, ezáltal megtekinteni.
- Lehetőség van még az ablakok közötti váltásra.
- Help menü (segítség)
- Részletes segítség kapható ezen keresztül a program használatáról angol nyelven.